Vernetzte IT-Systeme zeigen eine große Komplexität aufgrund ihres Aufbaus dynamischer und skalierbarer Komponenten. Die Komplexität begünstigt Störungen und bedarf somit konkreten und in der Praxis anwendbaren technologischen Lösungen. In den letzten Blogbeiträgen habe ich einen Überblick über Methoden und Techniken gegeben, um Störungen in vernetzten IT-Systemen zu erkennen und zu beheben. Wie steht es aber um die konkreten Technologien, die eine Sammlung von Techniken und Methoden verwenden? Über diese Technologien, die in der Praxis existieren, möchte ich Ihnen gerne einen Überblick geben. Dazu gehören unter anderem das Simple Network Protokoll oder Business Intelligence. Der Vorteil dieser Technologien ist, dass diese schon eine Kombination aus Methoden und Technologien von Haus aus mitbringen. So ist es möglich, mit geringem Aufwand grundlegende Funktionalitäten für die Störungserkennung zu etablieren.
Techniken, Methoden und Technologien – Ja was denn nun?
Wie sind die Technologien aber einzuordnen und welchen Platz nehmen diese gegenüber den Techniken und Methoden zur Störungserkennung ein? Folgende Darstellung (Abbildung 1) zeigt den Zusammenhang zwischen Techniken, Methoden und Technologien. Während die Techniken wie Regeln, Statistik oder Künstliche Intelligenz eine sehr technische und programmatische Ebene darstellen, haben die Methoden wie Detecting oder Tracing einen fachlicheren Bezug und sind anwendungsorientierter für die Praxis. Die Technologien jedoch fassen verschiedene Methoden und Techniken zusammen, bieten umfassendere Lösungen für bestimmte Praxisbereiche und Anwendungsfälle und erreichen somit einen noch höheren Grad an Anwendungsorientierung für die Praxis.
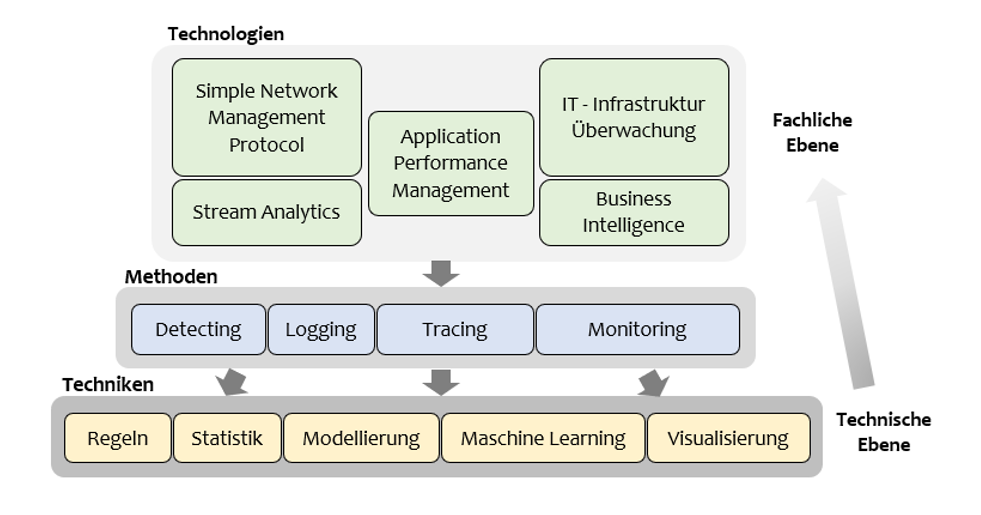
Abbildung 1: Zusammenhang zwischen Techniken, Methoden und Technologien (© Fraunhofer IAO)
Im Folgenden möchte ich Ihnen 5 Technologien vorstellen, die Ihnen in der Praxis weiterhelfen können:
1. Simple Network Management Protocol (SNMP)
Das Simple Network Management Protocol (SNMP) ist ein standardisiertes Protokoll zur Überwachung und Steuerung von IT-Komponenten mit dem Fokus auf die Netzwerkhardware. Mit diesem Protokoll können Netzwerkkomponenten überwacht, ferngesteuert, konfiguriert, Fehler erkannt und über diese benachrichtigt werden. Herausforderungen ergeben sich bei der Implementierung, da diese Fachwissen benötigt. Jedoch zeichnet sich das SNMP durch eine gute Standardisierung aus und es gibt eine breite Unterstützung von Betriebssystemen. Verwendet wird das SNMP sowohl für das Monitoring eines Systems als auch für die Netzwerkadministration.
2. IT-Infrastruktur-Überwachung
Diese Technologie wird für vernetzte IT-Systeme mit dem Fokus Funktionalität (inkl. Erreichbarkeit, vorhandener Festplattenspeicher oder auch Auslastungen von Prozessoren und dem Netzwerk) der IT-Komponenten eingesetzt. Auch werden historische Daten gesammelt, mit dem Ziel zwischen normalen und anormalen Mustern zu unterscheiden, um Störungen und Ursachen zu ermitteln. In der Praxis wird diese Technologie oft mit Monitoring verknüpft, um mithilfe von Dashboards, Kennzahlen und Alarme anzuzeigen. Auch wenn der Integrationsaufwand anfangs größer ist, sind IT-Infrastruktur-Überwachungswerkzeuge sehr ausgereift und unterstützen eine breite Anzahl an Prüfungen und Standards.
3. Stream Analytics
Diese Technologie wertet Ereignisströme aus, welche in einem verteilten IT-System, wie beispielsweise bei Bestellprozessen vorkommen. Solche Ereignisströme sollen erkannt und mithilfe von definierten Regeln verarbeitet werden. Reaktionen folgen, wenn die Regeln nicht eingehalten werden. Dies kann z.B. eine zu lange Durchlaufzeit eines Bestellprozesses sein. Herausfordernd ist jedoch, dass es keine Out-of-the-box-Lösung gibt, dementsprechend braucht es Expertenwissen für das Aufstellen von Regeln. Mehrwert bieten Aggregationen, um aussagekräftige Kennzahlen zu definieren, wie Durchschnitte oder Summen, die mit den vorhandenen Ereignisströmen in einem verteilten IT-System berechnet werden. Da Prozesse über Systemgrenzen hinweggehen, erlaubt diese Technologie auch Störungen über die eigenen Prozesse hinaus zu erkennen.
4. Business Intelligence (BI)
Business Intelligence (BI) hat zum Ziel, Geschäftswissen aus Daten zu generieren und somit Hilfe für Entscheidungen zu geben. BI hilft, Ursachen von Störungen in vernetzen IT-Systemen effizient zu ermitteln, denn eine Kernkompetenz von BI ist sowohl die Anbindung verschiedener Datenquellen als auch die Verarbeitung großer Datenmengen mit einem breiten Spektrum von Analysemöglichkeiten, historisch und prognostisch. Dazu gehören auch Künstliche Intelligenz, Statistik oder Data Mining. BI ist natürlich kein Tool zum Kaufen, sondern eine Sammlung aus Erfahrungen, Technologien und Know-how, was im Unternehmen kontinuierlich weiterwachsen muss. Heute ist BI jedoch zu einem Standard in vielen Unternehmen geworden.
5. Application Performance Management (APM)
Das Application Performance Management (APM) ist eine neue Technologie, die Web- und Cloud-Applikationen mit allen Gesichtspunkten in Bezug auf die fachliche Funktionalität überwachen soll. Ziel ist es, Auffälligkeiten im Verhalten von Anwendungen und ihrer Komponenten aufzudecken. Diese Technologie ist besonders für verteilte IT-Systeme entwickelt worden und verwendet viele Methoden und Techniken, die Störungserkennung kombiniert – wie Log-Analyse, Stream Analytics oder Tracing. Bisher ist APM auf Web- und Cloud-Anwendungen ausgelegt und benötigt Software-Agenten auf Webseiten. Es bietet aber Einblick in das Verhalten des Anwenders zu bekommen, Ursachen für Störungen leichter zu finden und auch das Verhalten des Systems aus Sicht des Anwenders zu untersuchen.
Die Qual der Wahl?
Mit den nun aktuellen Techniken, Methoden und Technologien zur Störungserkennung stellt sich natürlich auch die Frage, was nun am besten für das eigene vernetzte IT-System verwendet werden soll? Dieses hängt zum einen von verschiedenen Anforderungen an die Störungserkennung ab. Folgende Fragen können gestellt werden:
- Können Störungen in jedem Einzelfall erkannt werden?
- Gibt es statistische Werte für das Gesamtsystem?
- Gibt es eine rückblickende Diagnose und Ursachenerkennung?
- Ist die Kommunikation in Echtzeit möglich?
- Welcher Zugriff ist auf das System möglich?
- Welche Daten stehen zur Verfügung?
Es sind aber auch die individuellen Ziele des Unternehmens zu berücksichtigen und welche Zielgruppen, wie Kund*in, Manager, Entwickler*in oder Retail mit eingebunden sind. In Bezug auf neue und moderne Technologien, sind ältere Technologien wie die IT-Infrastruktur-Überwachung oft sehr ausgereift und genießen einen hohen Grad an Stabilität und Standard. Moderne Technologien – wie beispielsweise das Application Performance Management – integrieren oftmals diese schon bewährten Technologien. Die Frage nach einer Individualentwicklung von Störungserkennung ist schwer zu begründen, denn der Markt hat effiziente und ausgereifte Standardsoftware im Angebot. Für Standardprobleme sollten auf alle Fälle Standardlösungen eingesetzt werden.
Für eine Vertiefung in das Thema der Technologien oder auch zum gesamten Thema der Störungserkennung in vernetzten IT-Systemen gibt die vom Fraunhofer IAO und dem Anwendungszentrum KEIM erstellte Marktstudie zur »Überwachung und Störungserkennung in vernetzten IT-Systemen« weitere Einblicke.
Der nächste Blogbeitrag zeigt auf, dass es einen konkreten Zusammenhang zwischen einer guten Softwarequalität und der Störungserkennung in vernetzten IT-Systemen gibt. Wie nun eine gute Sicherung der Softwarequalität umgesetzt werden kann und was dazu gebraucht wird, beantworte ich im nächsten Beitrag der Reihe.

Leselinks:
- Marktstudie: Überwachung und Störungserkennung in vernetzten IT-Systemen
- Störungen in Vernetzten IT-Systemen: Eine Toolbox an Techniken für den praktischen Einsatz
