
Störungserkennung spart Geld, Zeit und Ressourcen und müsste daher in der Unternehmensstrategie fest verankert sein. Wie sieht aber die Realität in Unternehmen aus? In Zeiten von immer stärker vernetzten IT-Systemen ist es aufgrund der Komplexität immer eine große Herausforderung, diese zu überwachen und Störungen mit ihren Ursachen zu erkennen. Es führt aber kein Weg dran vorbei, diesem Thema mehr Aufmerksamkeit zu schenken. Denn Dienste müssen immer zur Verfügung, die Antwortzeiten schnell und Updates reibungslos integrierbar sein. In den letzten zwei Blogbeiträgen habe ich unter anderem Methoden zur Störungserkennung wie das Logging, Tracing, Detecting und Monitoring vorgestellt. Aber wie lassen sich diese Methoden in der Praxis umsetzen? Es sind bestimmte Techniken notwendig, um die erwähnten Methoden für den individuellen Use Case im Unternehmen anwenden zu können (Abbildung 1). Mit diesem Blogbeitrag möchte ich Ihnen einen Überblick über diese Techniken, Entscheidungshilfen und Empfehlungen an die Hand geben.
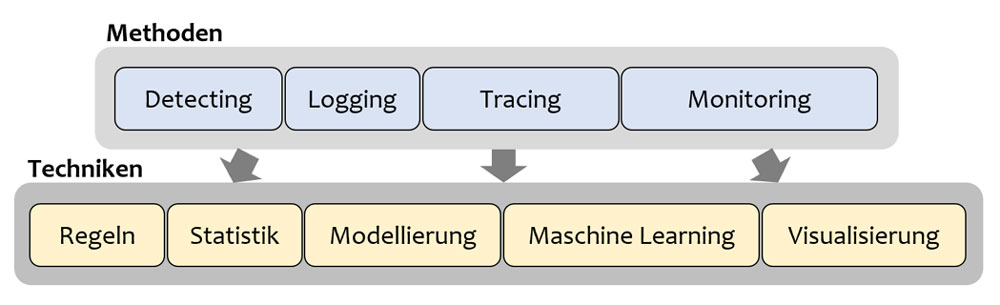
Abbildung 1: Übersicht der Techniken, die von den Methoden verwendet werden. (© Fraunhofer IAO)
Regeln – Alles einfach nur »Wenn-Dann«
Regeln werden grundsätzlich für die Überwachung von Störungen in vernetzten IT-Systemen eingesetzt. Diese definieren sich immer durch eine »Wenn-Dann-Logik«. Illustrieren lässt sich das an einem praktischen Beispiel: »Wenn« 80 Prozent der möglichen Anfragen erreicht sind, »dann« steigt die Antwortzeit des Servers exponentiell. Regeln sind einfach aufzusetzen, entweder in vorhandenen Monitoring-Tools oder auch direkt in der Software bei der Programmierung. Voraussetzung für die Definition solcher Regeln ist jedoch eine gute Kenntnis über das Verhalten des vernetzten IT-System. Auch sollte klar sein, dass mit verschachtelten Regeln die Komplexität steigt. Bleiben solche Regeln auf einem normalen Niveau, sind Regeln eine einfache Methode, um Störungen schnell zu erkennen. Daher ist auch die Empfehlung, Regeln auf jeden Fall einzusetzen, um wichtige Störungen herauszufiltern.
Statistik – Umgang mit empirischen Daten
Statistik ist die meistverwendete Technik, um empirische Daten zu analysieren. Besonders das Finden von Korrelationen und Vergleiche von Histogrammen können einen wesentlichen Beitrag zur Störungsfindung und auch zur Ursachenerkennung leisten. Hohe Netzwerkauslastungen der letzten Wochen können beispielsweise in Zusammenhang mit der Anzahl von Marketingaktionen gebracht werden, weil Kunden mehr kaufen. Voraussetzungen für den Einsatz dieser Technik sind Kenntnisse und Know-how im Bereich Statistik und der Umgang mit größeren Datenmengen. Es bieten schon viele Softwarelösungen grundlegende statistische Auswertungsfunktionalitäten, weswegen der Einstieg in diese Technik mit wenig Aufwand und hohem Nutzen verbunden ist.
Modellierung – Ein Abbild der Realität
Diese Technik modelliert ein Teilbereich aus der realen Welt des vernetzten Systems mit dem Augenmerk auf ein spezifisches Thema wie z.B. den Aufbau der Netzinfrastruktur (Abbildung 2). Der Vergleich des realen Systems mit dem Modell hilft Störungen und Ursachen besser zu erkennen (Abbildung 2, links). Voraussetzung dafür ist jedoch ein tiefes Verständnis des Systems, um überhaupt ein Modell aufzubauen. Die Empfehlung ist diese Technik nacheinander aufzubauen und klein anzufangen, orientiert am eigenen Wissensstand. So kann mit der Zeit diese Technik an Reife gewinnen.
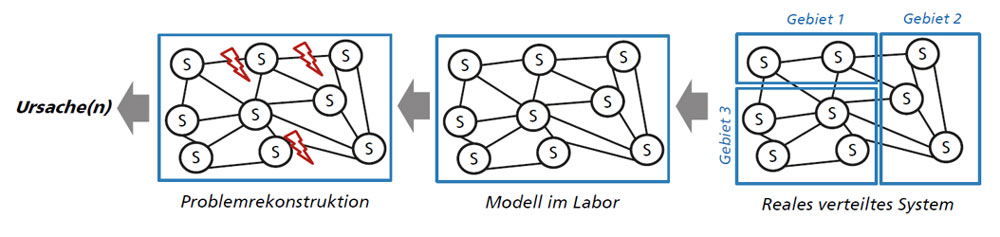
Abbildung 2: 13: Technik der Modellierung Abbild der realen Welt Modell (© Fraunhofer IAO)
Maschinelles Lernen – Erkennung von Verhalten
Maschinelles Lernen (ML) gehört zum Bereich der Künstlichen Intelligenz. Die Aufgabe in vernetzten IT-Systemen ist es, Unterschiede zwischen normalen Funktionalitäten und Störungen zu erlernen. Ein Beispiel für den Einsatz von ML ist die Untersuchung des Internetdatenstroms. Aufgrund des normalen Datenstrommusters ist es möglich, Veränderungen (Anomalien) zu erlernen, um beispielsweise Hackerangriffe zu erkennen. Verwendung findet ML besonders bei Tracing und Logging. Voraussetzungen für den Einsatz dieser Technik sind neben guten qualitativen Daten Kenntnisse und Erfahrungen. Nur so können die Ergebnisse auch gute Qualität liefern. Es bieten zwar auch schon viele Tools und Softwarelösungen ML an, jedoch muss die Theorie dahinter verstanden werden, um diese Technik auch verwenden zu können.
Visualisierung – Bilder sagen mehr als 1000 Worte
Die Visualisierung ist wohl die beste und bekannteste Technik für die Störungs- und Ursachenerkennung. Sie ist ein Schlüsselfaktor, um ein verteiltes IT-System mittels Diagramme und Graphen sichtbar und transparent zu machen. Hier sagen Bilder mehr als 1000 Worte. Besonders Dashboards sind ein beliebtes Instrument in der Praxis und helfen Informationen aggregiert zur Verfügung zu stellen. Es gibt wenige Voraussetzungen für den Einsatz von Visualisierung. In der Regel bieten Softwareplugins oder Logging-, oder Tracing-Tools Standard-Visualisierungen an, welche dann je nach Erfahrung weiter verfeinert werden können. Wichtig zu wissen ist: schon einfache Visualisierungen bringen einen weitreichenden Mehrwert, weswegen diese Technik unbedingt fokussiert werden muss.
Techniken beherrschbar machen
Die nun vorgestellten Techniken werden in der Praxis einzeln oder auch in Kombination von den Methoden zur Störungserkennung (Logging, Tracing, Detecting und Monitoring) verwendet. Das Ergebnis der Methoden ist jedoch nur so gut, wie auch die Techniken optimal angewendet werden. Daher bedarf es technische und fachliche Kenntnisse, um diese beherrschbar zu machen, die einen mehr, die anderen weniger. Besonders der Bereich des Maschinellen Lernens sollte in der Organisation separat organisiert sein, denn es verlangt eine tiefere Kenntnis über die Theorie und die Anwendung in der Praxis. Zusätzlich ist ein erlernter Umgang mit Big Data nicht unerheblich, da viele Daten verarbeitet werden müssen, wie eben beim Logging und bei der Tracing-Methode. Wichtig ist aber, dass kein Meister vom Himmel gefallen ist und es sich in der Praxis bewährt hat, mit kleinen Schritten anzufangen. Weitere Inhalte und Informationen zu diesem Thema lassen sich auch in der Marktstudie des Fraunhofer IAO und des Anwendungszentrums KEIM zum Thema »Überwachung und Störungserkennung in vernetzten IT-Systemen« finden.
Im nächsten Blogbeitrag stehen Technologien in den Anwendungslösungen, die in der Praxis Verwendung finden, im Mittelpunkt. Es wird auch die Frage beantwortet, wie die hier vorgestellten Techniken mit den Methoden der Störungserkennung (wie Logging oder Tracing) und den Technologien in den Anwendungslösungen in Verbindung stehen.
Leselinks:
- Marktstudie: Überwachung und Störungserkennung in vernetzten IT-Systemen
- Störungen in Vernetzten IT-Systemen: Vier konkrete Methoden, um Störungen zu erkennen
Kategorien: Digitalisierung
Tags: IT-Systeme, Störungserkennung