
Nachdem in den 90er Jahren das World Wide Web das Internet revolutionierte, sehen wir uns seit einigen Jahren einer weiteren revolutionären Entwicklung gegenüber: dem Grid-Computing (de.wikipedia.org/wiki/Grid-Computing). Beim Grid-Computing werden dezentrale Computer und Rechencluster über das Internet zu einem »virtuellen Supercomputer« zusammengeschlossen. So wird ein direkter Zugriff auf die Ressourcen des Grids, wie Rechner, Speicher, wissenschaftliche Instrumente und Experimente, Anwendungen, Daten und Sensoren bereitgestellt.
Seit 2001 betreibt das IAO gemeinsam mit einigen anderen Fraunhofer-Instituten das Fraunhofer Resource Grid (www.fhrg.fraunhofer.de). Seit 2005 die D-Grid-Initiative (www.d-grid.de/) ins Leben gerufen wurde, engagiert sich das Fraunhofer IAO auch dort in verschiedenen Bereichen des Grid-Computings. Der Schwerpunkt liegt dabei auf einer verbesserten Usability der Dienste, einer Verbesserung der Sicherheits-Architektur und der Entwicklung von Geschäftsmodellen für Ressourcen- und Service-Provider.
In diesem Zusammenhang möchten wir Ihnen einen experimentellen Grid-Ansatz vorstellen: LiDiC – Lightweight Distributed Computing. Bei diesem Ansatz wird eine »leichtgewichtige« Grid-Umgebung mittels normaler, JavaScript-fähiger Internet-Browser aufgespannt. Beliebig viele dieser Browser werden auf eine bestimmte URL gerichtet und mittels JavaScript und AJAX-Technologie werden Arbeitspakete an die Browser übermittelt. Die Arbeitspakete werden von den Browsern abgearbeitet und die Ergebnisse anschließend an den Server zurückgeschickt.
Der große Vorteil an diesem Ansatz ist, dass er keine Client-Installation benötigt, sodass sich im Gegensatz zu anderen Grid-Projekten, wie SETI@home oder dem World Community Grid, jeder Nutzer des Internets sofort an den Berechnungen beteiligen kann. Aufgrund des leichtgewichtigen Ansatzes könnte man sagen: LiDiC ist eine Grid-Umgebung auf Diät!
Die Abbildung 1 zeigt den zugrundeliegenden Aufbau: Ein Job-Master erstellt die Arbeitspakete, die von einem HTTP-Server auf die verfügbaren Web-Browser (Worker) verteilt werden. Die Ergebnisse der Worker werden an den Server zurückgeschickt, der diese dann dem Job-Master verfügbar macht.
Wie kann ein solches Grid im digitalen Alltag von Unternehmen und Privatpersonen erfolgreich eingesetzt werden? Eine Möglichkeit wäre ein firmeninterner Einsatz, da heutzutage in vielen Rechnern Multicore-Prozessoren laufen, die durch alltägliche Büroanwendungen nicht ausgelastet sind. Moderne Browser unterstützen eine effiziente Zuteilung von offenen Fenstern auf verschiedene Prozessorkerne, was bedeutet, dass jeder Mitarbeiter in einem oder mehreren Browserfenstern das firmeninterne Grid rechnen lassen kann, ohne dass sich das auf die Leistung der restlichen Anwendungen oder das Surfen im Internet auswirken würde.
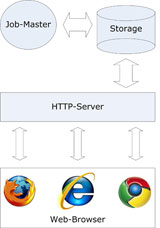
Abb. 1
Eine optimale Auslastung der firmeneigenen Computerressourcen wäre die Folge und aufgrund des leichtgewichtigen Ansatzes wäre es nicht erforderlich, auf allen Mitarbeiterrechnern eine Client-Anwendung nachzuinstallieren.
Darüber hinaus gibt es schon vereinzelt Versuche eines kommerziellen Einsatzes eines solchen Grids. Ein Beispiel hierfür ist die Firma PluralProcessing, die Betreibern von Webseiten Geld bietet, wenn diese ein Java-Applet in ihre Webseite einbinden. Mittels dieses Applets werden dann in den Web-Browsern der Seitenbesucher verteilte Berechnungen durchgeführt.
Der in diesem Beitrag vorgestellte Ansatz ist als Experiment zu sehen. Im Produktivbetrieb müssen hohe Lasten verarbeitet und darüber hinaus Synchronisations- und Sicherheitsaspekte beachtet werden. Außerdem entsteht aufgrund des gewählten HTTP-Protokolls und der Berechnungen in JavaScript ein großer Overhead, weshalb der Ansatz schnell ineffektiv werden kann, wird er auf die falsche Problemdomäne angewandt. Dennoch bietet die browserbasierte Grid-Infrastruktur die verlockende Möglichkeit, dass potenziell jeder Computer mit Internetanschluss Rechenzeit zu einem Grid beisteuern kann.
Details zum Experiment
Als Aufgabenstellung für das Experiment wählten wir die Berechnung des kürzesten Pfades
zwischen einem Startknoten und einem beliebigen Knoten in einem gerichteten Graphen (de.wikipedia.org/wiki/Graphentheorie). Typischerweise kommt für die Suche nach dem minimalen Abstand in einem gerichteten Graphen der Dijkstra-Algorithmus [Dijkstra59] zu Anwendung, der sich aber nur ungenügend parallelisieren lässt. Darum haben wir die in einem Google-Vortrag (nl.youtube.com/watch?v=BT-piFBP4fE) vorgeschlagene Breitensuche implementiert, bei der Parallelität über das MapReduce-Pattern [Dean04] eingeführt wird.
Abb. 2
Bei diesem Algorithmus durchläuft der Job-Master mehrere Iterationen der Breitensuche und ermittelt so das globale Optimum der kürzesten Wege im Graphen. Als Datensatz nutzen wir einen nach [Wenzel02] synthetisch generierten »Small-World«-Graphen mit 100.000 Knoten und 400.218 gerichtete Kanten (siehe Abbildung 2).
[Dijkstra59] E. W. Dijkstra. A note on two problems in connexion with graphs. Numerische Mathematik 1. S. 269–271. 1959.
[Wenzel02] L. Wenzel. Wie klein ist doch die Welt. Toolbox. 2002.
[Dean04] J. Dean, S. Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. OSDI. 2004.
Kategorien: Digitale Transformation
Tags: Softwaretechnik