

Für viele Anwender und Interessierte sind Algorithmen der Künstlichen Intelligenz undurchdringbare Blackboxes. Tatsächlich gibt es Verfahren, die selbst für Experten schwer zu fassen sind. Gleichzeitig aber sind die Abläufe vieler leistungsfähiger Algorithmen relativ leicht zu verstehen, ohne dass man Experte oder Expertin für KI sein muss.
Ich möchte in diesem Blogbeitrag auf drei solcher Verfahren näher eingehen und vor allem potenziellen Anwendern von KI dabei helfen, KI-Verfahren besser beurteilen zu können und damit den Einstieg in den eigenen Anwendungsfall zu erleichtern.
1. Entscheidungsbäume
Entscheidungsbäume sind die denkbar einfachsten Algorithmen. Hier werden Entscheidungsmöglichkeiten ähnlich den Verzweigungen einer Baumkrone dargestellt.
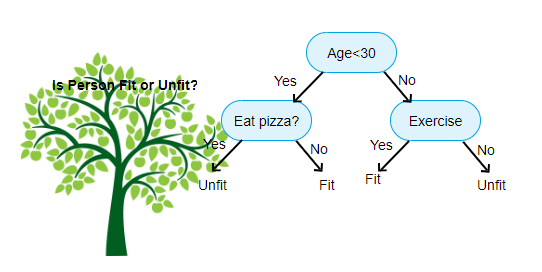
Quelle: https://www.aitimejournal.com/@akshay.chavan/a-comprehensive-guide-to-decision-tree-learning
Der vorliegende exemplarische Entscheidungsbaum-Algorithmus soll entscheiden, ob ein Mensch sportlich fit ist oder nicht. Dazu wird eine Reihe an Fragen durchlaufen, beispielsweise mit einem Chatbot, der Kunden Fragen stellt. Jede Antwort entscheidet darüber, welche Frage als nächstes gestellt wird. In unserem Beispiel: Ist der betrachtete Mensch 35, so wird anschließend gefragt, ob er sich sportlich betätigt. Ist er 17, erscheint die Frage nach Essensgewohnheiten wie häufigem Pizzaessen relevanter. Am Ende eines jeden Pfades steht eine Zuordnung zur Klasse »fit« oder »nicht fit«.
Der Clou ist nun der, dass der Algorithmus selber lernt, welche Fragen zu stellen sind und wie die Fragen je nach Antwort angeordnet werden müssen. Dies geschieht ohne aktives Zutun anderer. Er »lernt«, weil er nicht irgendwelche Fragen stellt, sondern intern nach gewissen Kriterien optimiert (ohne dass man es als Benutzer mitkriegen würde). Ein solches Kriterium könnte etwa die Teilungsgüte sein: Die zu durchlaufenden Fragen (oder Splits) werden so gewählt, dass eine möglichst trennscharfe Unterteilung zwischen den zwei Zielklassen (»fit« oder »nicht fit«) erreicht wird. Das Alter, Pizzaessen und körperliche Betätigung haben sicherlich großen Einfluss auf den sportlichen Zustand eines Menschen und werden entsprechend gewichtet.
2. Lineare Regression
Dieses Verfahren ist dem einen oder anderen bestimmt geläufig. Stellen Sie sich vor, sie versuchen den universitären Notendurchschnitt von zukünftigen Studenten anhand ihrer schulischen Notendurchschnitte vorherzusagen.
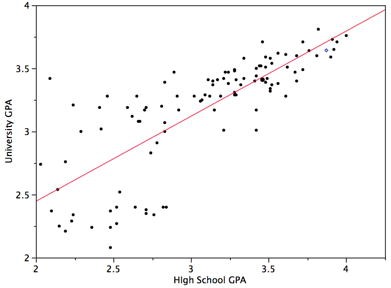
Quelle: http://onlinestatbook.com/2/regression/inferential.html
Die schwarzen Punkte zeigen Wissen aus der Vergangenheit: Den schulischen Notendurchschnitt von Studenten, deren universitärer Notendurchschnitt bereits bekannt ist. Der Algorithmus errechnet nun eine optimale Ausgleichsgerade (hier rot dargestellt; optimal heißt dabei, dass die Abweichungen in Summe möglichst klein sind). Diese Ausgleichsgerade zeigt also das bisherige Verhältnis von Schulnoten zu Hochschulnoten und lässt sich auf neue Studentengenerationen übertragen. So kann unser Algorithmus eine Prognose über den universitären Notendurchschnitt abgeben.
3. k-Nearest-Neighbor-Algorithmus (kNN)
Mit diesem Algorithmus lassen sich zu einem gegebenen Datenpunkt ähnliche Datenpunkte (»Nachbarn«) finden und den gegebenen Datenpunkt dann derjenigen Klasse zuordnen, welche bei den Nachbarn überwiegt.
Was abstrakt klingt, lässt sich leicht veranschaulichen: Stellen Sie sich vor, Sie sind Hautarzt und haben in der Vergangenheit viele Muttermale als gut- oder bösartig klassifiziert. Dabei vermuten Sie, dass die Länge und Breite des Muttermals eine entscheidende Rolle spielen. Aus vergangenen Diagnosen wissen sie also, welche Kombination von Länge und Breite zu welchem Ergebnis geführt hat. Um die zukünftige Diagnostik zu unterstützen, nutzen Sie den kNN. Auf der x-Achse tragen Sie die Breite, auf der y-Achse die Länge auf. Blau bedeutet gutartig, rot bösartig. Der gelbe Punkt steht für ein noch unklassifiziertes Muttermal. kNN soll Sie dabei unterstützen, eine Diagnose zu treffen.
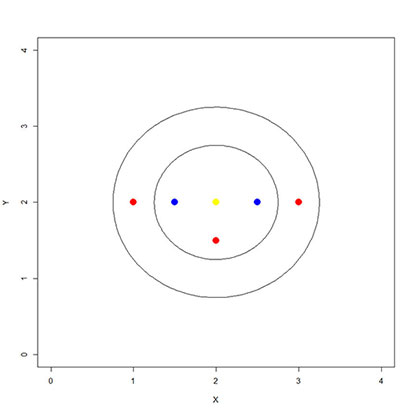
Quelle: Fraunhofer IAO
Das k im Namen kNN steht übrigens für die Anzahl der zu betrachtenden Nachbarn. Natürlich kann der Algorithmus zu verschiedenen Ergebnissen kommen, je nachdem, wie k gewählt wird.
Wählen Sie k=3, so wird der Algorithmus das neue Muttermal (also den gelben Punkt) als gutartig klassifizieren (d.h. der blauen Klasse zuordnen), denn zwei von drei Nachbarn sind blau und nur einer von drei Nachbarn ist rot). Wählen Sie hingegen k=5, so überwiegen die roten Nachbarn (drei von fünf) und das neue Muttermal wird als bösartig klassifiziert.
Die Suche nach dem optimalen k stellt eine nicht-triviale Aufgabe dar und hängt stark vom Anwendungsfall ab. Ebenso muss man sich Gedanken machen, wie man »Abstand« oder »Nachbarschaft« definiert. Bei Zahlen im zweidimensionalen Raum (wie im Beispiel) geht das einfach. Aber auch für höherdimensionale Räume stehen Standard-Maße zur Verfügung.
Weitere Anwendungsfälle der oben genannten Verfahren sind
- automatische Bestimmung eingehender Dokumente (z.B. Rechnung, Mahnung oder Terminanfrage)
- selbstständige Extraktion von Namen, Adressen, Datumsangaben etc.
- Vorhersage laufender oder zukünftiger Prozesse, zum Beispiel Fertigungsprozesse
Hat man einmal das Grundprinzip verstanden, ist der Schritt zur nächsten Verallgemeinerung oder Weiterentwicklung der Verfahren nicht mehr so groß. Auch bei komplexeren Algorithmen ist nicht mehr entscheidend, die genaue Funktionsweise zu verstehen, sondern zu wissen, welche Verfahren sich für welche Problemstellungen eignen und welche Stellschrauben es jeweils gibt, um die Vorhersagegüte der Verfahren zu erhöhen.
Wer tiefer in die Thematik einsteigen will, ist herzlich eingeladen, unsere kostenlose Seminare im November zu besuchen oder mich direkt anzusprechen – ich freue mich auf Ihre Fragen und Ihre KI-Anwendungsideen!
Mittelständische Unternehmen stehen vor der Herausforderung, trotz guter Auftragslage heute, ihre Produkte, Organisationsformen und Geschäftsmodelle von morgen vorauszudenken. Wie können die eigenen Geschäftsprozesse mit Hilfe von KI verbessert werden? Welche Potenziale für neue Geschäftsmodelle schlummern in KI-Anwendungen? In der Blogreihe gibt das BIEC als Innovationspartner des Mittelstands Antworten auf diese und viele weitere Fragen rund um Digitalisierung und Transformation.
Leselinks:
- Seminar »Data Science und Künstliche Intelligenz« am 13./14. November 2019
- Veranstaltung »Künstliche Intelligenz: Was ist für mich drin?« am 20. November 2019
- Veranstaltung »Textverstehen mit Künstlicher Intelligenz« am 20. November 2019
- Alle Beiträge zum Wissenschaftsjahr 2019 »Künstliche Intelligenz«
- Alle Beiträge zur Blogreihe »Business Innovation Engineering Center BIEC – Künstliche Intelligenz nutzen«
- Alle Veranstaltungen zum Thema »Künstliche Intelligenz«
Kategorien: Digitale Transformation, Künstliche Intelligenz
Tags: Business Innovation Engineering Center BIEC - Künstliche Intelligenz nutzen, KI - Künstliche Intelligenz, Wissenschaftsjahr 2019 - Künstliche Intelligenz