
Mit dieser Blogreihe beleuchte ich die unterschiedlichen Aspekte und Dimensionen der Störungserkennung. Für Unternehmen kann ein gutes Investment in die Vorbeugung von Störungen in vernetzten IT-Systemen einen erheblichen Nutzen bringen. Nicht nur Kosten und Personalressourcen werden damit gespart, sondern auch die eigene Unternehmensstrategie gestärkt. Hierfür braucht es aber Know-how über die technischen, methodischen und technologischen Ansätze für eine nachhaltige Verankerung der Störungserkennung im Unternehmen. In der Theorie hört sich das sehr gut an, wie sieht es aber in der gelebten Praxis aus? Inwieweit wird die Störungserkennung in Hinblick auf Standardisierung und zukünftige Entwicklungen in Unternehmen gelebt und welche Anforderungen ergeben sich daraus?
Um diesen Fragen auf den Grund zu gehen, haben wir am Fraunhofer IAO im Jahr 2020 eine Marktstudie zur »Überwachung und Störungserkennung in vernetzten IT-Systemen« veröffentlicht. Dabei wurden Expert*innen aus dem Anwendungs-, Beratungs- und Anbieterumfeld befragt und wichtige Erkenntnisse hervorgebracht, welche ich im Wesentlichen nun vorstellen möchte. Die herausgegriffenen Schwerpunkte helfen Ihnen, Störungserkennung anhand der schon gelebten Praxis besser umzusetzen und das Theoretische besser in die Praxis einordnen zu können.
Spezifikation – Konkrete Anforderungen bilden die Grundlage
Bei der Spezifikation geht es um konkrete Anforderungen, die an eine Störungserkennung in einem vernetzten IT-System gestellt werden. Sie beschreibt, was eine Störungserkennung leisten muss. Die Spezifikation ist damit sehr bedeutsam, da sie die entscheidende Grundlage für eine Ausgestaltung zur Störungserkennung legt. Unsere Studie zeigt, dass solche Anforderungen nicht nur technischer Natur (Programmieren) sein dürfen, sondern die gesamte Organisation umfassen müssen, von der Entwicklung, über den Betrieb bis hin zum Support. Solche Anforderungen sind beispielsweise die Art der Zusammenarbeit bei der Entwicklung, agil oder nicht agil? Störungserkennung sollte sich an der Unternehmensstrategie orientieren. Davon abgeleitete Ziele – so auch die Anforderungen – sollten somit in eine fachliche Ebene (»Was«) und technische Ebene (»Wie«) getrennt werden. Metriken und Messwerte können dabei als messbare Einheiten dienen, um die definierten Ziele zu überprüfen. Das kann beispielsweise die Verfügbarkeit des Systems oder die CPU-Auslastung von Servern sein.
Datenintegration – Daten richtig verwenden
Datenintegration beschreibt die grundsätzliche Verarbeitung der Daten, damit Störungserkennung umgesetzt werden kann. Entscheidend ist es jedoch, die Daten richtig zu verwenden. Nur Daten zu besitzen, hilft meistens nicht, vielmehr müssen diese auch effizient und informationsgewinnend verarbeitet werden. In der Praxis werden sehr gerne Monitoring-Systeme eingesetzt, die von vielen Bereichen des Unternehmens Daten sammeln, verarbeiten und visualisieren. Die Integration solcher Daten von Dritt-Systemen gestaltet sich dann jedoch als Herausforderung, was auch in der Studie gezeigt werden konnte. Dritt-Systeme können als »Black-Box« wahrgenommen werden. Oft fehlt der Einblick in die Funktionen von In- und Outputs, was eine Integration dieser Daten von Dritt-Systemen für die Störungserkennung erschwert. Im Vorfeld Vertragsverhandlungen mit den Drittanbietern zu führen, um Schnittstellen bereitgestellt zu bekommen, ist ein Vorteil, um hier Störungserkennung zu etablieren. Weiter ist auch das Testen der Datenintegration wichtig. Besonders der Einsatz von »Health-Endpoints«, um den Gesundheitszustand von System-Komponenten zu untersuchen, wird in der Praxis gerne eingesetzt. Dabei handelt es sich um Software-Bausteine, die über Komponenten Auskunft geben, wie Abbildung 1 zeigt. Hier besitzt eine Anwendung eine Schnittstelle (Health-Endpoint), über welche spezifische Werte über den Gesundheitszustand abgefragt werden können.
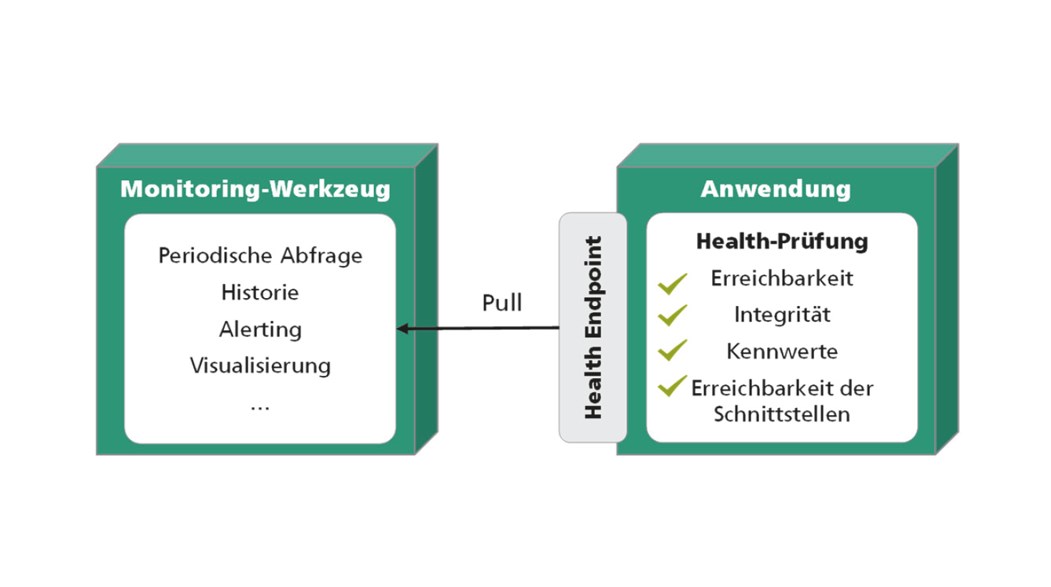
Abbildung 1: Darstellung für die Verwendung eines Health Points für eine Anwendung (© Fraunhofer IAO)
Störungserkennung – Man muss den Normalfall vom Sonderfall unterscheiden
Ganz klar zeigt die Praxis einen Bedarf an Störungserkennung. Jedoch kann dies nur passieren, wenn der Normalfall des Systems vom Sonderfall (Anomalie) unterschieden werden kann, so die Expert*innen. Eine Anomalie kann beispielsweise ein Muster im Datenverkehr sein, welche über die normale Nutzung hinaus geht und für ein Angriff auf das System deuten kann. Somit ist es wichtig, auf allen Ebenen des Systems zu definieren, was normal ist und das schon von Beginn an. Dies ist aber auch in der Praxis eine herausfordernde Aufgabe, wie die Studie zeigt. Viele Faktoren müssen berücksichtigt werden, um das »Normale« zu definieren, wie beispielsweise eingesetzte Technologien, den Kunden, Betriebssysteme oder auch zeitliche Aspekte wie Feiertage. Eine bewährte Methode, um dem »Normalfall« und »Sonderfall« auf den Grund zu gehen, ist das End-to-End-Monitoring. Aus Kundensicht werden die Funktionalitäten periodisch automatisiert getestet. Dies kann zum Beispiel das Anlegen eines Kunden in der Datenbank sein oder auch das Durchlaufen eines Bestellprozesses. Störungen können hier schnell gefunden werden. Auch Prognosen mittels Statistik oder auch der Einsatz von Künstlicher Intelligenz, welcher weiten Einzug gefunden hat. Hier zeigt die Umfrage, dass gerade für die Erkennung von Anomalien (z. B. im Anfragen über das Netzwerk) Maschine Learning zu einem wichtigen Werkzeug geworden ist.
Standardisierung – Immer noch ein »Sorgenkind«
Der Grad der Standardisierung zeichnet sich in der Praxis als »mager« aus. Das bestätigt die Studie. Die riesige Menge an Hard- und Softwarekomponenten, Adaptern, Software-Plugins oder unterschiedlichen Datenarten erschweren die Standardisierung von Schnittstellen und Protokollen. Vielmehr können sie sogar in Konkurrenz zueinanderstehen. Daher ist es laut den Expert*innen der Befragung wichtig, frühzeitig mit Fehlercodes zu arbeiten, die schon in den standardisierten Protokollen (vgl. HTTP, HTTPS oder TCP) von Software-Komponenten mit integriert sind. Auch der Einsatz eigener spezifischer Fehlercodes ist von Beginn der Entwicklung hilfreich, wie zum Beispiel die Fehlercodes von Microsofts Blue-Screen. In diesem Kontext sind auch sogenannte »Exception Policies« ein bewährtes Mittel, um festzulegen, wie mit Fehlern umgegangen werden soll und wo die Ursache der Störung ist. Ein klassisches Beispiel dafür sind Stracktraces.
KI, Microservices und IT-Automatisierung – die Themen der Zukunft
Zukünftige Entwicklungen, die sich in der Praxis laut der Studie weiter etablieren werden, sind vor allem Künstliche Intelligenz (KI), Microservices und IT-Automatisierung. KI wird in Zukunft weiter eine unterstützende Rolle spielen. Bessere Techniken und Methoden innerhalb KI erweitern auch stetig ihren Einsatz. Jedoch ist zu beachten, dass sie Vergangenheitsdaten von einem stabilen System benötigt werden, um optimal lernen zu können, so die Expert*innen. Mit vernetzten IT-Systemen ist das Thema Skalierbarkeit an vorderster Front und bedeutet, dass Funktionen separat aufgeteilt und verwaltet werden müssen. Auch dies zeichnete sich in der Studie ab. Dieses »Separation of Concerns« kann nur mittels Microservices umgesetzt werden, die ganz bestimmte Aufgaben erfüllen. Dies kann ein Verarbeitungs-Script, eine Log-Aufgabe oder auch eine Datenbank sein. So sind Microservices in der Praxis zu einem Design-Pattern geworden und werden die Zukunft weiter prägen. Für die immer weiterwachsenden Datenmengen ist die IT-Automatisierung ein großes Thema in der Praxis. Grundfunktionen, wie die Integration neuer Systeme oder für die Erstellung neuer Systemübersichten, sollen in der Störungserkennung automatisiert umsetzbar sein, so die Studie. Jedoch bleibt die Herausforderung, große vernetzte IT-Systeme für eine optimale Automatisierung zu konfigurieren.
Besonders an Standards muss noch weitergearbeitet werden, denn diese bilden eine wichtige Grundlage für ein gutes Zusammenspiel aller Komponenten in einem vernetzten IT-System. So hatte sich beispielsweise die Microservice-Architektur in den letzten 5 bis 10 Jahren durch Standardisierungen soweit herauskristallisiert, dass heute Lösungen wie beispielsweise Kubernetes für vernetzte IT-Systeme ein einfaches Aufsetzen von Microservices ermöglichen. Zum Abschluss der Reihe werde ich im letzten Blogbeitrag Best Practices und Handlungsempfehlungen vorstellen, welche in der Marktstudie herausgearbeitet wurden. Themen werden neben der Unternehmensstrategie auch die Themen Standardisierung oder Systeme Dritter sein.
Leselinks:
Kategorien: Digitalisierung
Tags: IT-Systeme, Störungserkennung