
Störungen gibt es in der digitalisierten Welt zu Genüge: Eine Mail wird nicht versandt, oder das Internet zu Hause funktioniert plötzlich nicht mehr. Jeder hat schon solche Störungen erlebt. Aber woran liegt das? Im letzten Blogbeitrag wurde schon in das Thema über die Arten von Störungen eingeführt. Auch wurden schon grundsätzliche Methoden vorgestellt, um Störungen in vernetzten IT-Systemen zu erkennen, wie das aktive und passive Monitoring.
Störungen in vernetzten IT-Systemen zu erkennen ist das eine, viel wichtiger ist es jedoch, die Ursachen der Störungen zu identifizieren, damit diese verhindert werden und somit erst gar nicht auftreten können. So können auch weitere Störungen vermieden als auch die aktuelle Störung behoben werden. Dies ist seine sehr komplexe Aufgabe geworden, da das Erkennen von Ursachen konkreter Herangehensweisen und die Unterstützung unterschiedlicher Technologien bedarf. Wie können Ursachen von Störungen in verteilten IT-Systemen erkannt werden? In den folgenden Ausführungen möchte ich Ihnen vier konkrete Wege aufzeigen, die in Wissenschaft und Praxis Verwendung finden. Dazu gehören das Monitoring, das Logging, das Tracing und das Detecting. Die Erfahrung zeigt, dass mit dem richtigen Einsatz dieser Methoden wesentliche Grundlagen für die Störungserkennung gelegt sind und diese schon einen Beitrag zur Einsparung von Ressourcen und Kosten aufgrund von Störungen leisten.
Logging-Methode – einfach und schnell
Die Logging-Methode wird in allen Bereichen der Praxis eingesetzt. Sie hat zum Ziel, Informationen in Form von Log-Einträgen von sämtlichen Komponenten im vernetzten IT-System zu sammeln und zu analysieren, wie Abbildung 1 zeigt. Log-Einträge können von der Datenbank sein, von Servern, bei denen die CPU-Auslastung oder die aktuelle Anzahl der Anfragen geloggt werden. So ist es möglich, tiefere Erkenntnisse über Störungen zu bekommen.
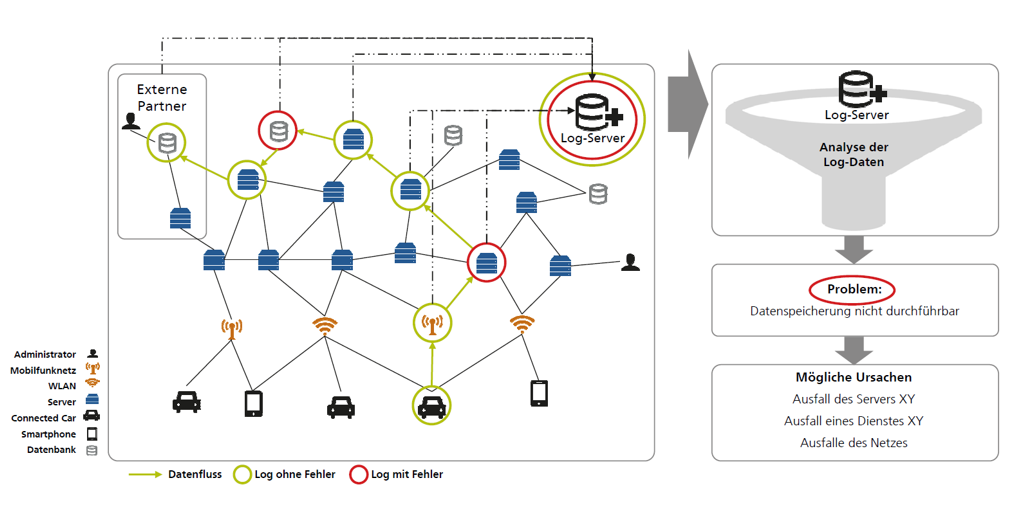
Abbildung 1: Übersicht über die Logging-Methode (© Fraunhofer IAO)
Idealerweise werden die Log-Einträge zentral in einer Log-Datenbank gespeichert, analysiert und es wird versucht, die Ursache zu finden. Es sind dabei nicht viele Vorrausetzungen notwendig, um Logging im Unternehmen zu betreiben. Benötigt wird neben den normalen IT-Kenntnissen eine Datenbank, in die geloggt werden kann und die Logs müssen entsprechend erstellt werden, vorzugsweise auch im Code selbst. Etwas Erfahrung in der Datenauswertung reicht, um erste Erkenntnisse sammeln zu können. Der große Vorteil ist, dass Logs schnell erzeugt und verarbeitet werden können. Jedoch ist es ratsam, nur das Nötigste zu loggen. Zu viele Log-Einträge erschweren wiederum die Auswertungen, denn die Komplexität steigt mit der Menge an Daten.
Tracing-Methode – auf Spurensuche der Datenpakete
Die Tracing-Methode kommt zum Einsatz, wenn der Weg der Datenpakete von Beginn bis zum Ende verfolgt wird. Auf dem Weg werden dann zusammenhängende Daten und Informationen der Wegpunkte (Komponenten wie Server, Router oder auch Software) gesammelt, wie Abbildung 2 zeigt. Dies hilft, Abläufe und Verbindungen zwischen einzelnen Hard- und Softwarekomponenten besser zu verstehen. Neben der Logging-Methode, mit der man vereinfacht gesagt einfach »los-loggen« kann, sind hier die Voraussetzungen etwas höhergesteckt. Da es sich hier um ein gezieltes Sammeln von Informationen handelt, müssen an gezielten Wegpunkten konkrete Informationen historisch festgehalten werden. Dies bedeutet, dass bei den entsprechenden Hard- und Softwarekomponenten eine Funktionalität hinterlegt sein muss, um entsprechende Informationen weiterzugeben. Der große Vorteil ist, dass Ursachenerkennung mit dieser Methode viel effizienter umgesetzt werden kann, da die Historik und die Wegpunkte der Datenpakete schon aufgezeichnet sind. Auch können weitreichendere Datenanalysen durchgeführt werden. Für die Auswertung von Tracing-Daten werden auch gerne statistische Methoden und auch Maschinelles Lernen eingesetzt.
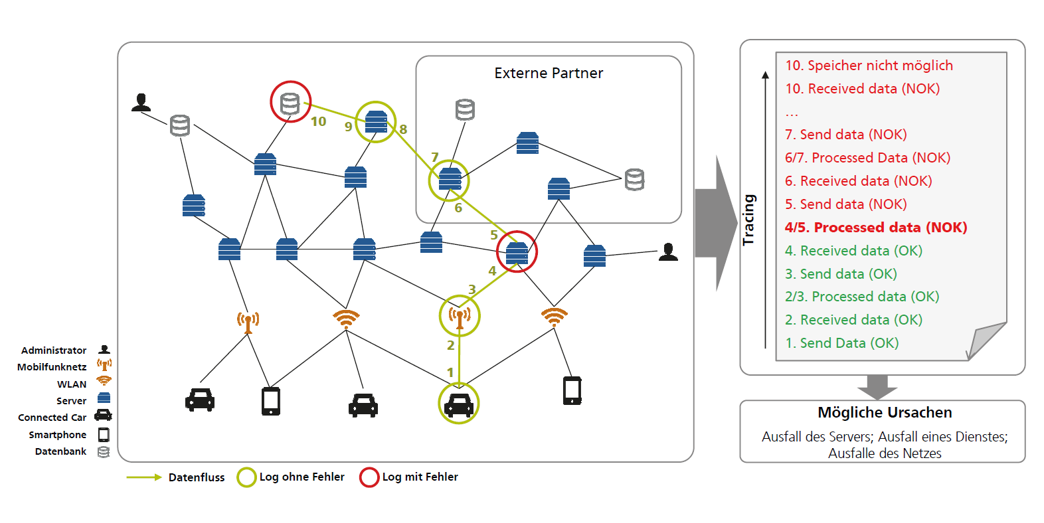
Abbildung 2: Übersicht über die Tracing – Methode (© Fraunhofer IAO)
Detecting-Methode – Der Agent mit der Lizenz zum Melden
Im Vergleich zu der Logging- und Tracing-Methode werden bei der Detecting-Methode Agenten (Software- oder Hardwarekomponenten, wie Temperatur- oder CPU-Sensoren) eingesetzt, die als Agenten Knotenpunkte überwachen und ggf. relevante Ereignisse übersenden. So kann beispielsweise ein Agent an einer Netzwerkschnittstelle über einen plötzlichen höheren Netzwerk-Traffic eine Meldung geben. Voraussetzungen sind die Integration in die Soft- oder Hardware des vernetzten IT-Systems, was schon mit der Entwicklung berücksichtigt werden muss. Dies bedeutet somit auch einen höheren technischen Aufwand. Jedoch müssen keine großen Datenauswertungen gemacht werden, da die Informationen der Agenten eventbasiert sind. Der wesentliche Vorteil dieser Methode ist die einfache Visualisierung ohne große vorherige Datenauswertung. Auch erlaubt diese Methode, einen tieferen und schnellen Einblick in das Gesamtsystem zu bekommen.
Monitoring-Methode – Analysieren ist gut, sehen ist besser
Datenverarbeitung und -analyse sind immer eine gute Sache, aber wie die Daten aussehen und diese auch verständlich zu visualisieren, macht den großen Unterschied. Die Monitoring-Methode ist die gängigste Methode in Forschung und Praxis. Sie visualisiert meist per Dashboards die Gegebenheiten eines vernetzen IT-Systems. Ursachen lassen sich beim Monitoring anhand von Erfahrungen gewinnen. Auch werden gerne Expert*innen herangezogen, die die Ergebnisse des Monitorings interpretieren und Empfehlungen abgeben. Das Monitoring arbeitet mit Daten, die von jeder der anderen hier genannten Methoden gewonnen werden können. So werden dann das Logging, das Tracing, oder das Detecting visualisiert. Störungen lassen sich damit gut erkennen. Monitoring ist aber auch geeignet für die Ursachenerkennung. Es hilft, technische und fachliche Kennzahlen über das System bzw. den Geschäftsprozess zu erfassen. Besonders folgende Bereiche können mit Monitoring abgedeckt werden:
- Verfügbarkeit (von Systemen, Services der Anwendungen)
- Kapazität und Leistung (Leistung von Komponenten, CPU- und Speicherauslastung)
- Sicherheit (Überwachung von Firewalls oder nicht-autorisierten Zugriffen)
Voraussetzungen für das Monitoring gibt es wenige. Viele Lösungen bzw. Hard- und Software bringen schon Standard-Visualisierungen mit sich und eslassen sich auch viele Visualisierungstools auf dem Markt finden.
Erkennung der Ursachen braucht eine Strategie
Grundsätzlich ist die Erkennung von Störungen ein wesentlicher Schritt in verteilten IT-Systemen. Jedoch ist es wichtig, hier nicht stehen zu bleiben und das Erkennen der Störungen jedes Mal zu feiern. Diese sind nur Symptome von Ursachen. Natürlich bleibt aber immer die Frage: Wo anfangen? Es braucht eine gewisse Strategie, die Methoden für die Störungserkennung gezielt und somit effektiv einzusetzen. Da die Methoden zur Ursachenerkennung komplexer sind, muss die Strategie schon in der Organisation bzw. im Management anfangen und dort präsent werden. So wird die Ursachenerkennung schon von Anfang an bei der Entwicklung eines IT-Systems mitberücksichtigt. Des Weiteren sollte zu der Strategie auch der Aufbau von Know-how gehören, denn Expertise ist für einen effektiven Einsatz der Methoden notwendig. So kann Ursachenerkennung sich gut mit der Zeit etablieren und sich in die immer stärkere Vernetzung der IT-Systeme optimaler integrieren. Für eine weitere Vertiefung zum Thema der Methoden zur Störungserkennung lassen sich in der Marktstudie des Fraunhofer IAO und des Anwendungszentrums Keim mit dem Titel »Überwachung und Störungserkennung in vernetzten IT-Systemen« mehr Informationen finden. Die Studie ist Teil der Schriftenreihe »Digitale Transformation in KMU« des Business Innovation Engineering Centers (BIEC), welches vom Ministerium für Wirtschaft, Arbeit und Wohnungsbau Baden-Württemberg gefördert wurde.
Im nächsten Blogbeitrag wird es um die technische Perspektive gehen, denn die Methoden zur Störungserkennung bedienen sich natürlich wichtiger Technologien, wie beispielsweise der Künstlichen Intelligenz.
Leselinks:
- Marktstudie: Überwachung und Störungserkennung in vernetzten IT-Systemen
- Störungen in Vernetzten IT-Systemen: Wie Störungen einfach definiert sind und erkannt werden können
Kategorien: Digitalisierung
Tags: IT-Systeme, Störungserkennung