

Triple KI – Data Science durchgängig gedacht! Claudia Dukino und Damian Kutzias promovieren zu der Frage, wie datenbasierte Projekte erfolgreich zu anwendbaren KI-Lösungen umgesetzt werden können. In einer gemeinsamen Blogreihe bündelt das KI-Tandem seine Kompetenzen und Forschungsergebnisse und veranschaulicht, wie die Verzahnung von Prozessen, Tätigkeiten und Technologien von der Ideengenerierung bis hin zur Inbetriebnahme neuer Lösungen in Unternehmen Mehrwerte schaffen kann.
Das KI-Projekt (Künstliche Intelligenz) scheint sich dem erfolgreichen Ende zu nähern: die Data Scientists berichten begeistert von ihren Erfolgen und demonstrieren die KI in der Anwendung. Voller Überzeugung startet das Marketing und schnell sind erste Kunden für die neuen KI-Services gefunden. Doch dann kommt die Ernüchterung: Die Daten wurden bisher manuell exportiert und vorverarbeitet, für die Speicherung wurde eine Projektdatenbank aufgesetzt und auch die Anwendungen laufen bisher wahlweise auf einer virtuellen Entwicklungsmaschine oder lokal bei den Data Scientists. Für die Sensoren ist nicht geklärt, wie diese angemessen verwaltet und mit Updates versorgt werden. Auch das Monitoring für die KI im Betrieb ist bisher lediglich grob angedacht. Schnelle Entscheidungen müssen getroffen werden und Entwicklungssysteme werden zu Betriebssystemen, womit technische und organisatorische Schulden aufgebaut werden.
Risiko 1: KI-Lösungen werden als isolierte Prototypen entwickelt
Lösungsvorschlag: Durchgängige und integrierte Betrachtung von KI-Projekten im Unternehmenskontext
Der gerade beschriebene, fiktive Extremfall mag polarisieren, doch zeigt die Praxis, dass zumindest Teile davon immer wieder vorkommen und scheinbar aussichtsreiche Projekte zu einem zweifelhaften Ergebnis führen oder sogar scheitern. Auch Literatur, Medien und Lehrmaterialien, insbesondere in Form von bestehenden Data Science-Vorgehensmodellen, begünstigen manche dieser Probleme: Die technologischen Elemente künstlicher Intelligenz sind neu und spannend und daher oft im Fokus. Wenngleich das durchaus verständlich und gerade im Sinne der Fortbildung sinnvoll ist, so schwingt doch ein großes Risiko mit: Unternehmen aus allen Branchen müssen heute aus Konkurrenzdruck, Kundenanforderungen oder unerschlossenem Potenzial heraus datenbasierte Services und KI entwickeln. Wenn solche Unternehmen nur partielle Hilfestellungen erhalten, erhöht sich somit das Risiko, dass Aufwände und wesentliche Herausforderungen falsch eingeschätzt werden, was zu den eingangs dargestellten Problemen führen kann.
Auch wirtschaftliche Entscheidungen können eine Rolle spielen: Das vollumfängliche Entwickeln einer KI-Lösung, welche sauber in die Unternehmenssysteme und Prozesse integriert ist, kann je nach Anwendungsfall umfangreiche Ressourcen erfordern. Da bei KI-Systemen im Vorhinein nicht immer klar ist, ob bzw. inwiefern die gesetzten Ziele auch wirklich erreicht werden können, ist ein paralleles Entwickeln der notwendigen »klassischen« Komponenten sowie der relevanten Schnittstellen ebenfalls ein Risiko. Als Konsequenz werden solche Entwicklungen oftmals erst im Anschluss an die gezeigte Machbarkeit durch einen KI-Prototypen umgesetzt, was zu umfangreichen nachgelagerten Aufwänden, eventuell sogar zu eigenen Umsetzungsprojekten nach dem KI-Prototyp führen kann.
Risiko 2: Investitionen an den falschen Stellen führen zu Verlust
Lösungsvorschlag: Integrationskonzepte und klassische Komponenten parallel konzipieren und frühzeitig eine nachgelagerte Umsetzung planen
Das Thema der Daten- und Systemarchitekturen sollte dementsprechend bereits frühzeitig konzeptionell mitgedacht werden, sodass fehlende Komponenten und ebenso Schnittstellen und damit Integrationspunkte rechtzeitig erkannt und angemessen geplant werden können. Als mögliche Hilfestellung können Strukturschema sowie Referenzarchitekturen herhalten, welche man zum Konzipieren der eigenen Systemarchitektur nutzen kann: Bestehende Komponenten werden eingetragen und notwendige fehlende Komponenten sowie deren Vernetzung ebenfalls. Dabei können Referenzarchitekturen als einfache Checklisten unterstützen: Man prüft, welche Komponenten relevant sind und reduziert somit das Risiko, wichtige Elemente zu vergessen.
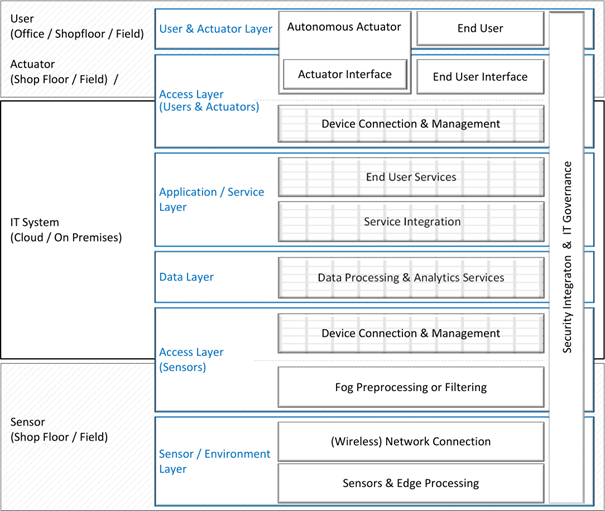
Abbildung 1: Strukturschema für eine IoT-Architektur (Internet of Things) aus “On the Complexity of Cloud and IoT Integration: Architectures, Challenges and Solution Approaches”, Kutzias et al., 2019.
Ein Strukturschema ist eine Möglichkeit, seiner Architektur Kontext zu geben: Die eigene Architektur muss nicht auf der grünen Wiese erstellt werden, sondern kann in eine semantische Struktur integriert werden. Je nach Komplexität können dabei verschiedene Teilstrukturen zugrunde gelegt und der Rest nur als Referenzmaterial genutzt werden. Beispielsweise können die sechs blauen Ebenen aus Abbildung 1 (begonnen bei »Sensor / Environment Layer«) die Struktur vorgeben.
Zusammenfassend lässt sich sagen, dass erfolgreiche KI-Projekte weit mehr erfordern als nur das Erstellen eines KI-Prototyps. Gerade bei komplexen Systemen mit Sensorik und Live-Daten müssen oft mehrere Komponenten neu erstellt, angepasst oder in bestehende Systeme integriert werden. Durch eine mindestens konzeptionelle Planung parallel zur Entwicklung eines KI-Prototypen können Aufwände für diese Umsetzungen sauber geplant und somit Risiken verringert werden.
Dieser Beitrag ist Teil einer Blog-Reihe, in der wir (Claudia Dukino und Damian Kutzias aus dem Bereich Digital Business) uns in den kommenden Monaten mit den Herausforderungen datenbasierter Projekte beschäftigen und dazu Mensch, Technik und Organisation im Einklang betrachten werden.
Leselinks:
- Triple KI: Die drei Säulen erfolgreicher KI-Implementierung im Unternehmen
- Parallelbeitrag von Claudia: Prototyp heißt nicht fertig – erst in Menschen denken, dann handeln!
- Schulung »Strukturierte Durchführung von KI-Projekten«
- KI am Fraunhofer IAO
- Methodisches Vorgehen zum KI-Einsatz für KMU
- SmartAIwork-Reihe »Automatisierung und Unterstützung in der Sachbearbeitung mit künstlicher Intelligenz«
Kategorien: Arbeitswelten (New Work, Connected Work)
Tags: Blogreihe Data Science, Digital Business Innovation, KI - Künstliche Intelligenz, Unternehmensentwicklung